
今天的“始终在线”和“始终可用”环境要求您的业务确保基础设施和数据具有维持24x7x365可访问性所需的冗余和弹性。确保您的业务在发生灾难时能够保持业务连续性的一个关键方面是有一个适当的业务连续性计划。
适当的规划是制定有效的业务连续性计划的关键要素之一。
首先,让我们来看看这个问题——什么是业务连续性计划?它的目的是什么?如何创建一个有效的?它与灾难恢复计划有何不同?
什么是业务连续性计划?
要开始创建业务连续性计划(BCP),您需要首先了解业务连续性计划到底是什么。经常业务连续性计划与a相混淆灾难恢复计划.然而,尽管业务连续性计划与灾难恢复密切相关,但它们是分离的。
业务连续性计划涉及在受到灾难影响时,您的业务将如何继续交付产品和服务的总体战略。它概述了意外事件,不仅包括技术基础设施将如何转移到替代系统,还包括业务流程、人力资源、资产、第三方关系,以及可能受到中断影响的业务的任何其他方面,以及这些将如何维持可接受的服务水平。

业务连续性计划的目的是什么?
业务连续性计划允许您的业务提前计划可能发生的意外事件和允许处理业务中断的战略过程。这是一个非常关键的过程。如果你不能制定一个计划如何处理某个中断你的生意,如果场景中展开,你可能会陷入一个场景,每个人都努力保持一个水平的业务,同时,制定程序动态和没有任何真正的深谋远虑。
如何创建一个有效的业务连续性计划
业务连续性计划(BCP)的需要和目的是极其重要的。现在,如何为您的业务创建BCP呢?需要考虑和包含什么?您的BCP中需要包含几个关键的考虑事项和信息。
这些包括:
- 重要联系人和关键团队成员
- 清点并确定业务中可能受灾难影响的部分
- 进行风险评估和影响分析
- 风险评估可帮助您识别和分析可能影响业务的事件,包括灾难。例如,位于美国佛罗里达州的企业无疑会将飓风作为潜在的业务干扰因素纳入其风险评估中。
- 影响分析报告分析风险评估中发现的风险对您业务的潜在严重性影响
- 为业务服务创建灾难恢复和应急计划
- 确定适合您的业务的RTO和RPO值——您的业务关键型服务可以停机多长时间?你愿意丢失多少数据?
- 创建并执行业务关键数据/系统的备份
- 将数据复制到异地
- 创建自动故障切换计划,使故障切换过程自动化
- 测试DR故障转移,并继续利用从每次测试中获得的经验教训改进BCP
BCP和DRP的区别
这在某种程度上已经涉及到,但是,业务连续性计划(BCP)与灾难恢复计划(DRP)有什么不同?如果您这样想,BCP是两者之间更全面和全面的计划,因为它必须考虑在特定中断期间您的业务将如何受到影响的所有方面。
这包括直接受影响的物品和间接相关的物品。它不仅包括技术方面,还包括您业务的任何资产,包括您的人员。在技术、人员、地点、服务、时间等方面需要做出哪些改变。因此,必须全面考虑每一件事,以充分理解你的业务如何继续运作。
的灾备计划(DRP)有更具体的目的。灾难恢复计划集中于解决导致中断或业务中断的特定问题。例如,如果主生产站点的一个主要服务器故障导致操作故障转移到您的容灾设施,DRP将专注于修复和恢复到生产服务器的连接,无论这是否需要更换硬件或数据恢复。
在这种情况下,业务连续性计划将涉及到故障切换到灾难恢复站点的所有逻辑方面。需要进行哪些网络更改?由于DR设施正在进行操作,您的人员需要进行哪些流程和程序更改。
一般来说,你的BCP和DRP会携手合作,保持你的业务运行,同时恢复正常的业务运作。
在上面的示例中,将故障转移到容灾环境的场景引用为一种情况,在这种情况下,您的业务连续性计划将启动,并利用故障转移到复制的虚拟机,以允许业务继续运行。复制可以是业务连续性计划中非常重要的一部分,因为它提供了在站点级具有弹性的方法。如果生产站点发生灾难,复制环境将处于备用状态,随时准备接管操作,以便业务能够继续运行。
让我们看看如何使用188abc金博宝 并了解Vembu如何轻松地将生产虚拟机复制到容灾环境。
使用Vembu BDR套件配置虚拟机复制
将业务关键型虚拟机复制到容灾位置是支持业务连续性计划的好方法。复制提供了一种依靠技术基础设施和连接性进行业务操作的方法,即使您的主要生产站点已经关闭。
Vembu使您的业务连续性计划在这方面变得容易,通过自动化的方式,您可以在第二个位置创建VM副本。使用Vembu BDR Suite设置关键业务虚拟机的复制是一个简单的五步过程。
要开始创建复制作业,请单击虚拟机复制菜单并选择VMware vSphere.
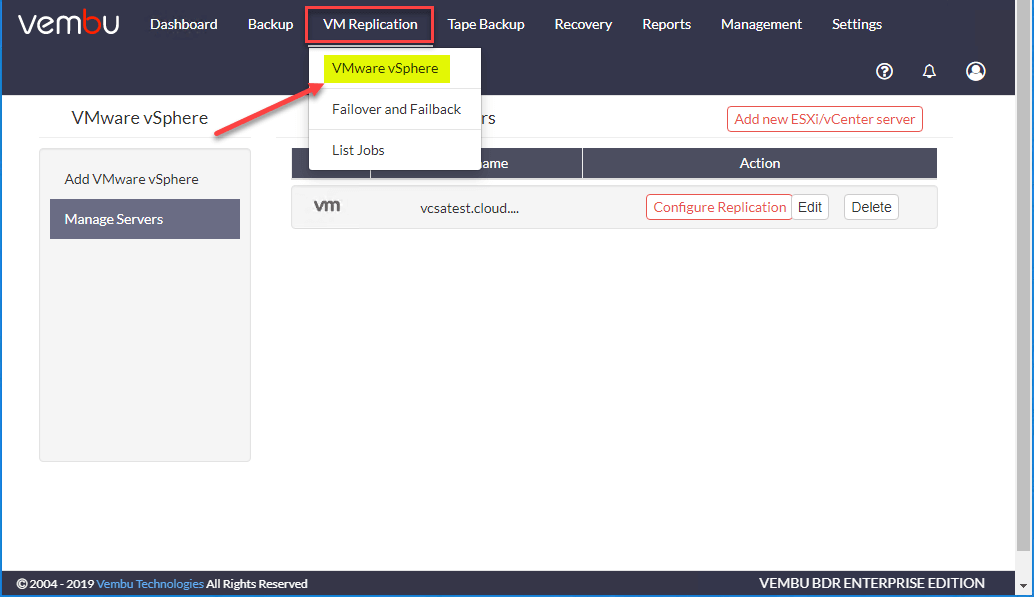
你会想同时拥有你的源vCenter连接和您的目的地vCenter连接已添加到Vembu。在复制作业配置期间,您将选择源虚拟机,然后选择目标环境。在下面的屏幕上,您可以配置复制在包含源虚拟机的vCenter连接上。
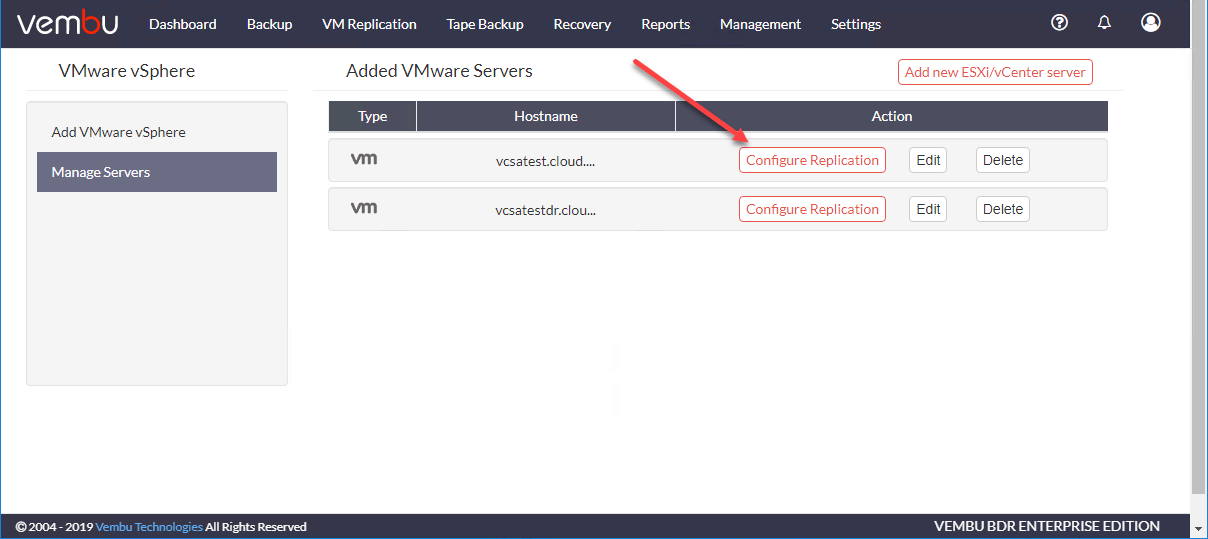
Vembu允许您在vCenter服务器管理的不同集群中探索ESXi服务器上的虚拟机。
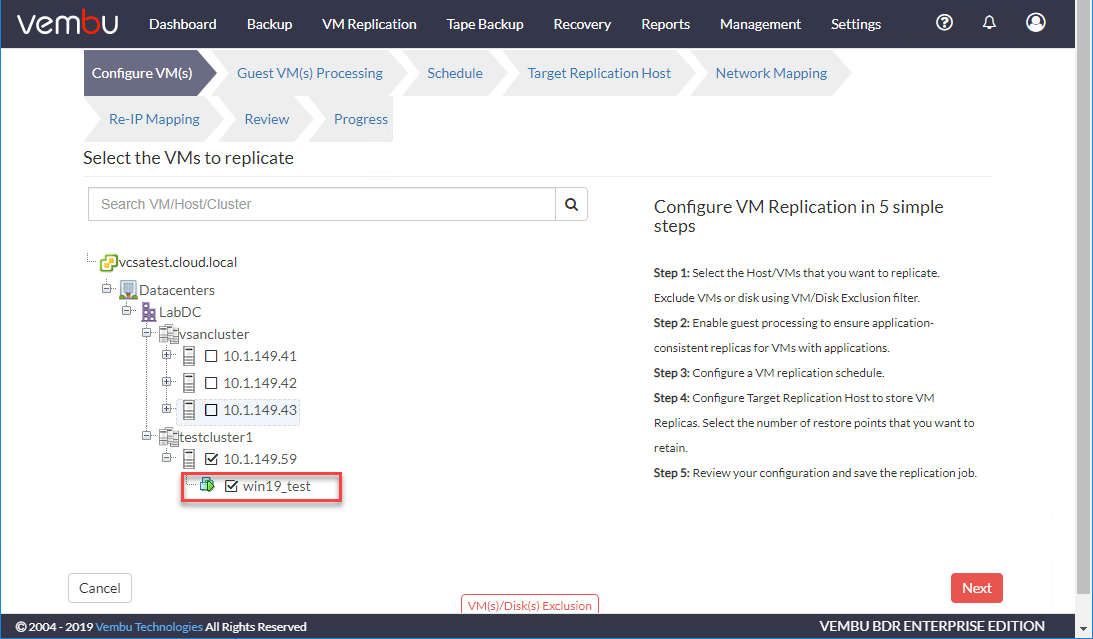
客人处理允许您为将要复制的虚拟机配置应用程序感知的复制。就像在备份时启用此功能一样,Vembu应用程序感知处理可以确保应用程序数据保持一致状态,并且在复制过程中不会发生数据损坏。
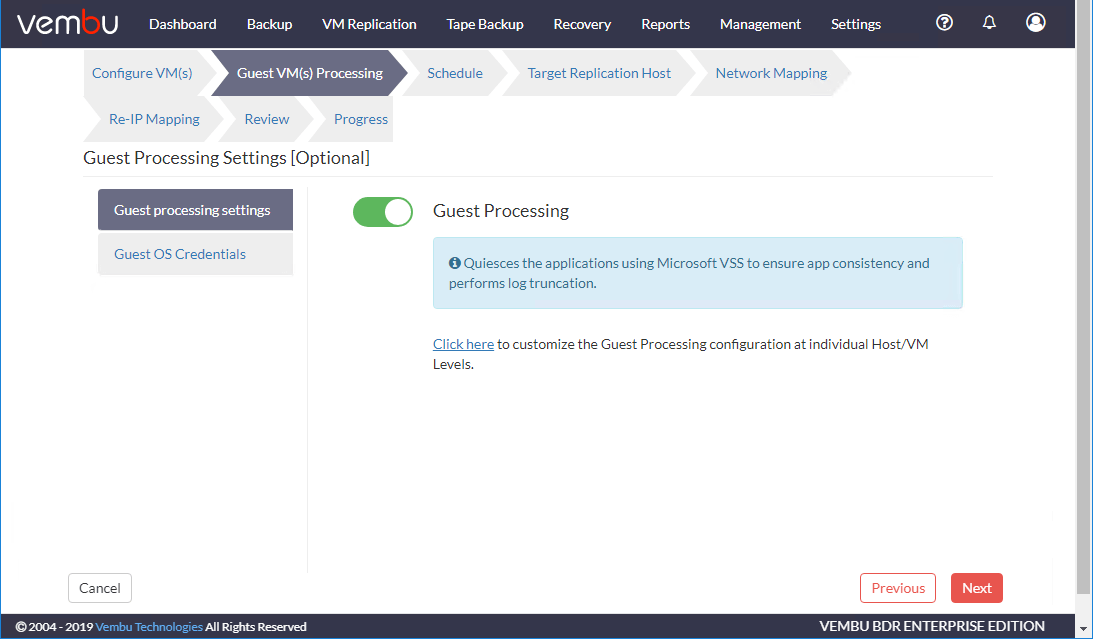
Guest Processing的第二个组件是配置来宾操作系统的凭证.这允许Vembu与来宾操作系统VSS编写者交互,使VM静默,以捕获一致的应用程序数据。
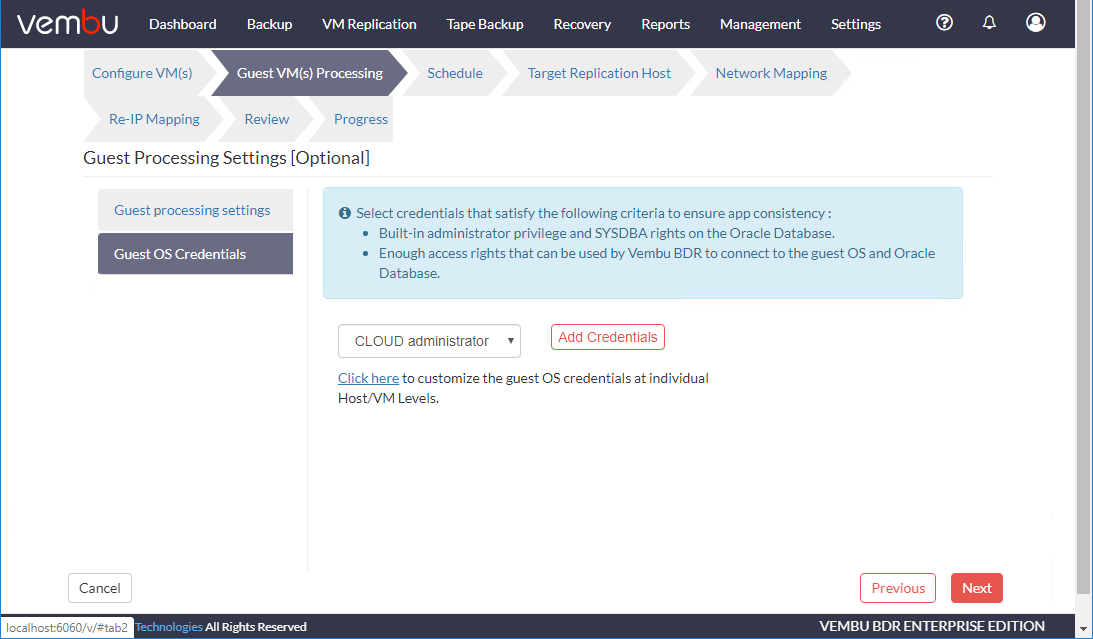
接下来,配置复制作业频率的计划。默认情况下,Vembu将每小时复制一次您的虚拟机。
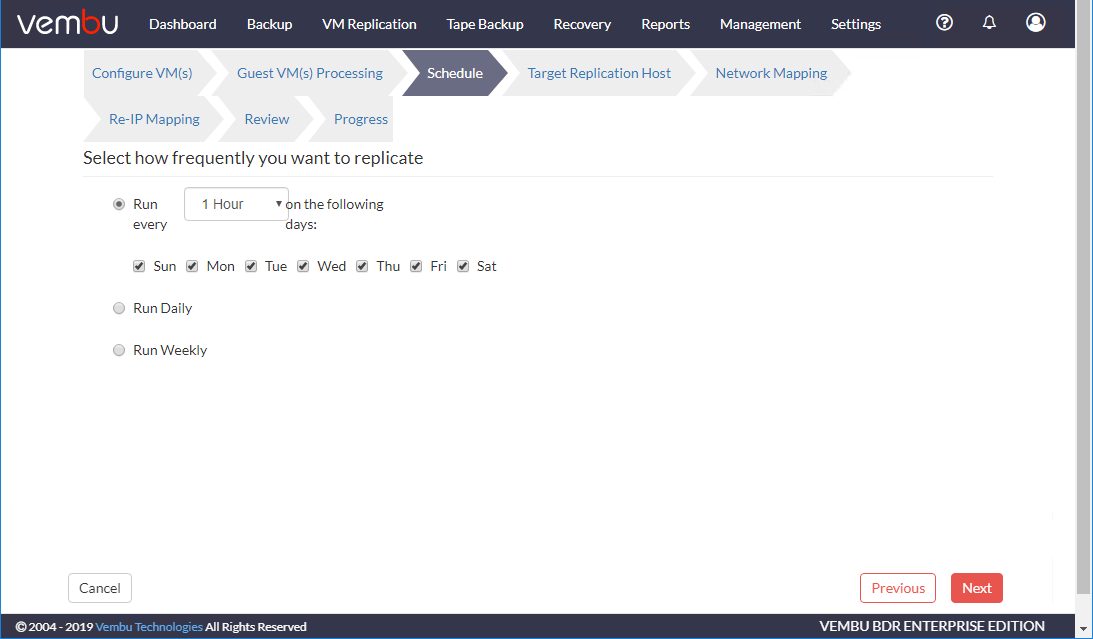
选择目标复制主机.这里你会想要改变VMware服务器将成为容灾设施中的vCenter服务器。选择ESXi主机、数据存储、副本后缀名和保留次数。
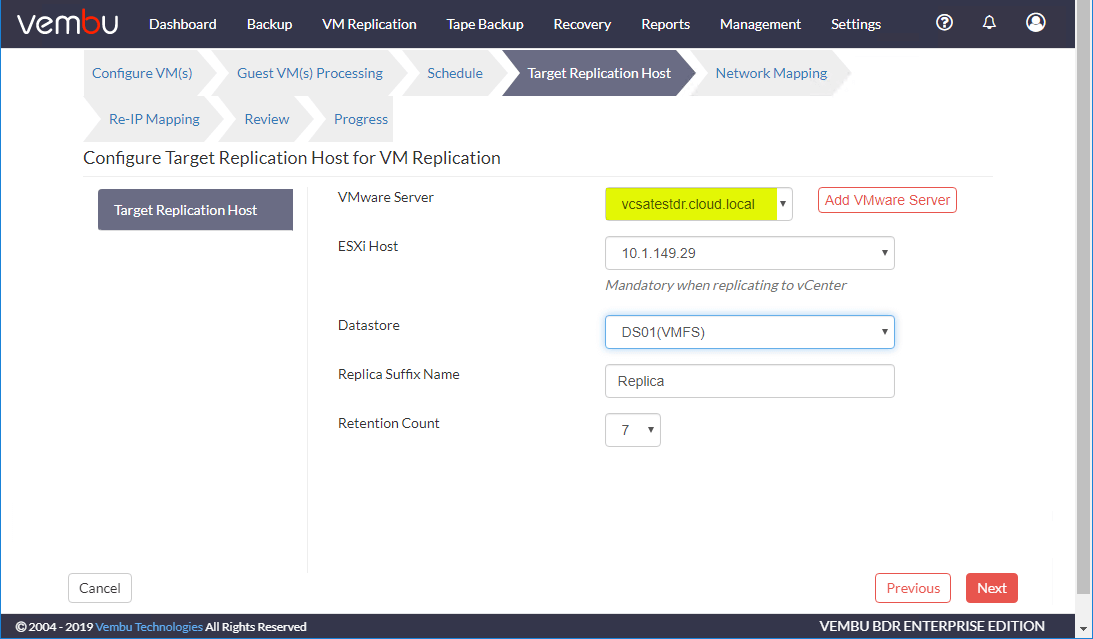
的网络映射这是Vembu真正开始在故障切换时重新配置复制虚拟机的地方。在此屏幕上,您可以映射连接到DR vSphere环境中的VM的端口组。如下所示,源VM端口组已连接到虚拟机网络,目标虚拟机端口组已绑定网络博士.
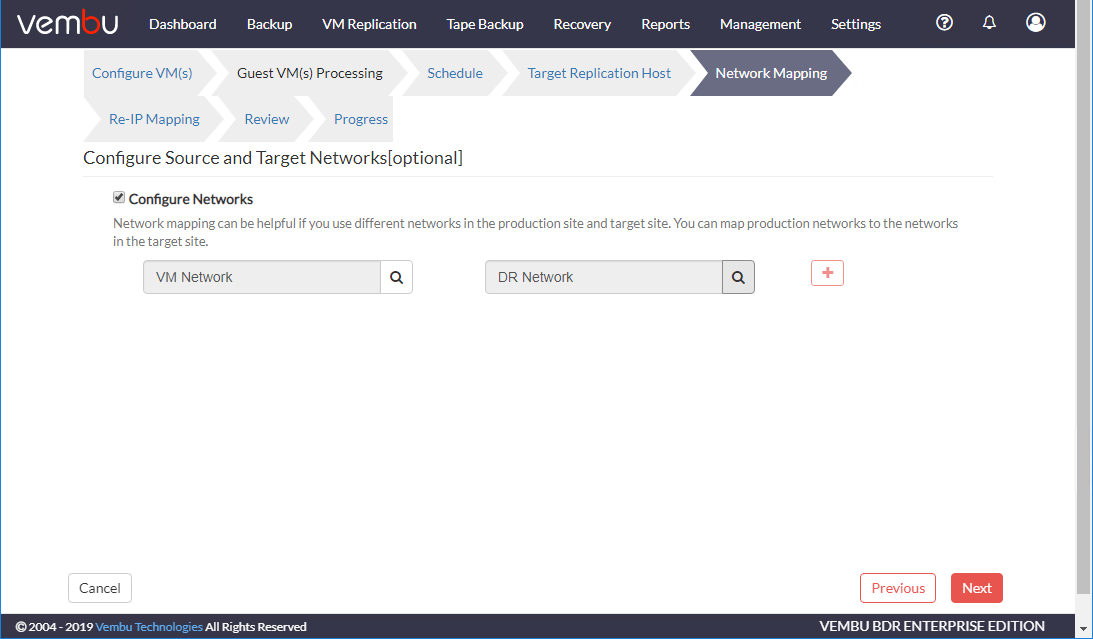
除了可以修改复制虚拟机绑定的端口组外,还可以添加端口组网络重新ip映射规则自动更改复制虚拟机的IP地址,以匹配容灾环境的子网。
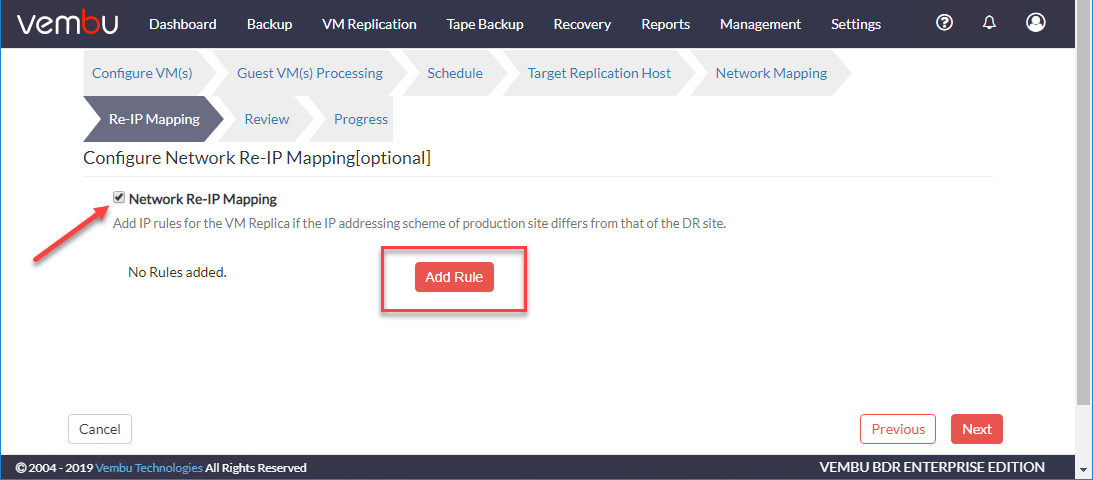
当你点击添加规则按钮,您将看到网络重IP映射对话框。这里输入要重新分配虚拟机的源IP地址和虚拟机副本地址。
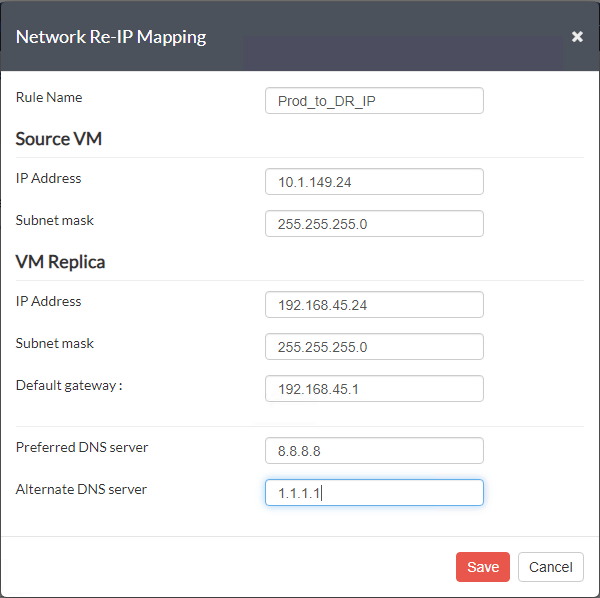
一旦你点击拯救时,复制任务将添加Re-IP规则映射。
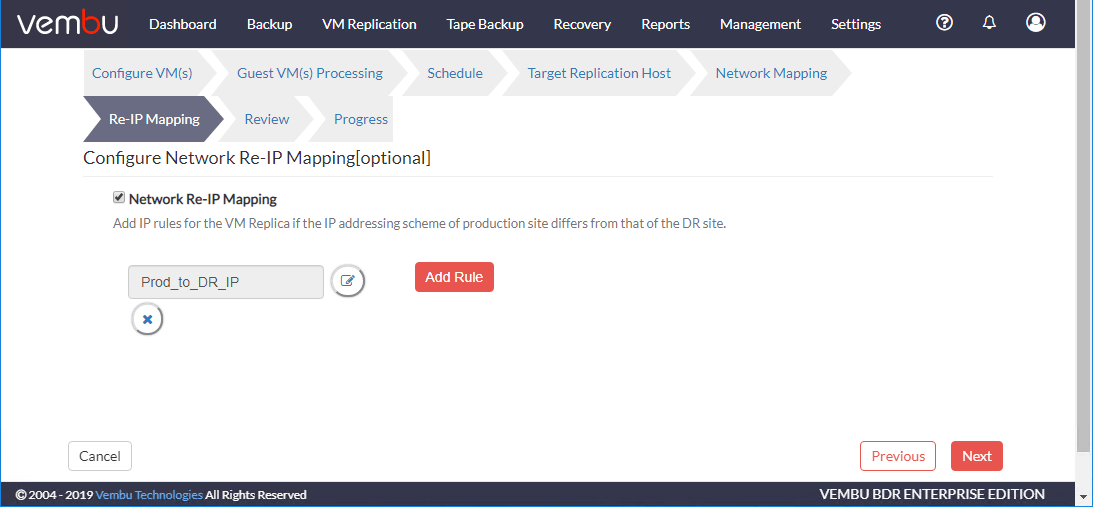
检查复制作业配置设置。
一旦你点击保存复制,您将看到“配置完成”对话框。点击好啊.

VM复制作业将开始创建复制作业中包含的虚拟机的初始副本。单击“绿色三角形”以查看复制作业的状态。
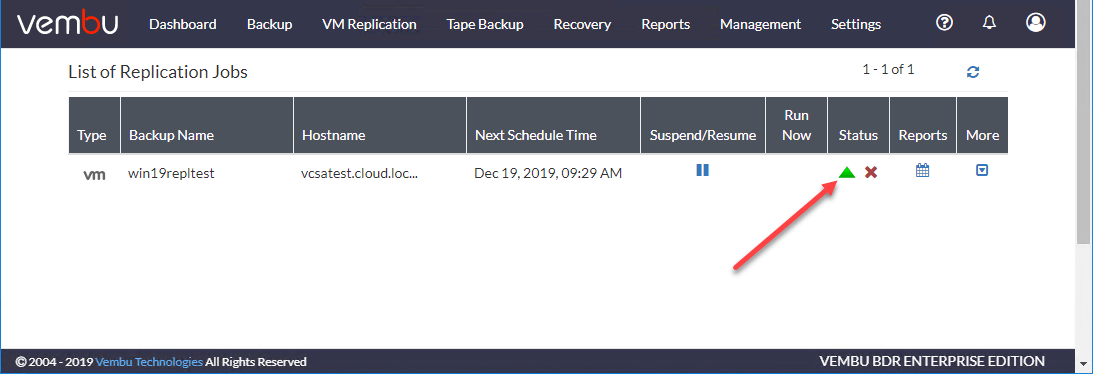
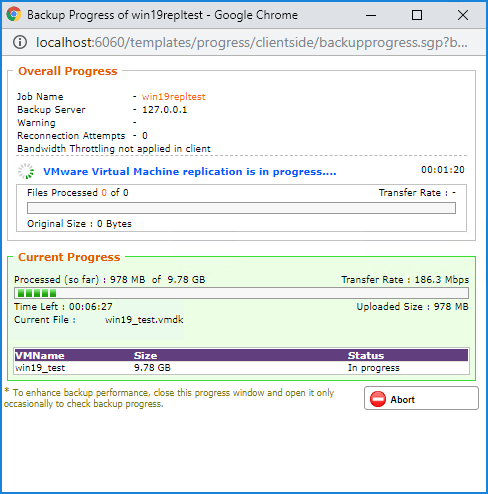
单击视图状态按钮后,您将看到总体进展对话框,其中详细说明复制作业中正在执行的当前进度和任务步骤。
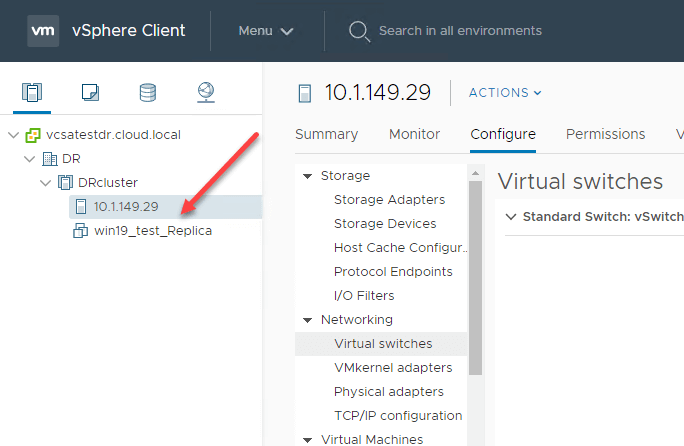
在目标vSphere环境中,您应该看到在该环境中创建的复制虚拟机。
使用Vembu BDR套件自动故障转移和故障恢复
Vembu不仅提供了在生产和容灾设施之间复制数据的工具,而且还提供了以编程方式从生产工作负载切换到容灾工作负载的自动化功能。业务连续性计划的全部目的是保持一定的生产力水平,即使在发生灾难或影响业务的事件时也是如此。
将生产虚拟机复制到其他位置的全部目的是为了在主生产站点宕机时保持生产效率。但是,即使将虚拟机复制到不同的位置,仅故障切换到虚拟机辅助副本的过程也可能是一项大型任务,而不需要自动化。
Vembu提供了Failover和Failback机制来简化生产和dr之间的转换。让我们看看如何轻松地配置它。
点击故障切换和回切在虚拟机复制菜单。
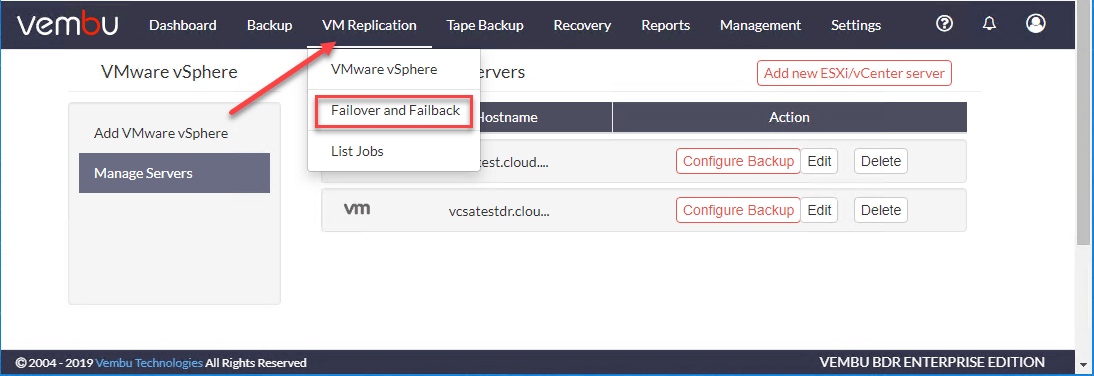
您将看到在Failover和Failback列表下列出的复制作业。点击恢复.
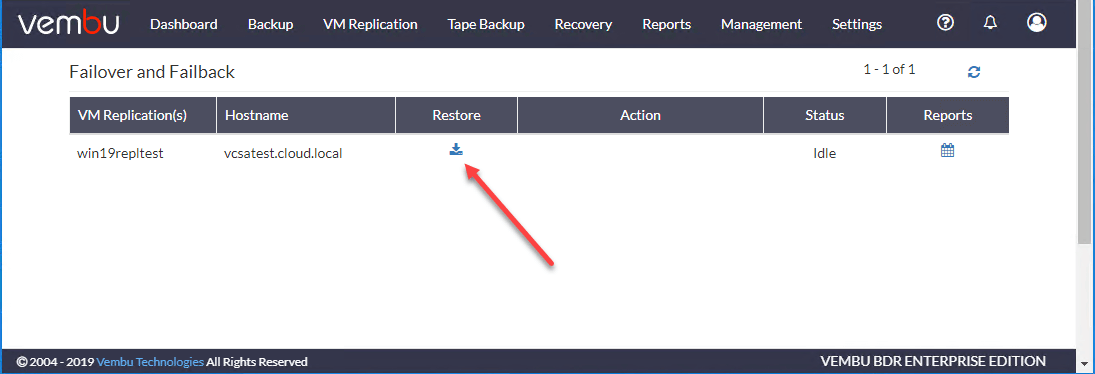
接下来,您将选择恢复类型,其中包括:
- 故障转移—在目标主机上切换原虚拟机到副本虚拟机的操作
- 完成故障转移-使用Undo Failover/Permanent来完成副本的Failover状态
- 故障转移/退回选项
- 确定退回—使用“撤消Failback”/“提交Failback”选项最终确定虚拟机副本的Failback状态
- 文件级恢复—从VM Replica恢复指定的文件和文件夹
在下面的屏幕上,让我们选择故障转移将生产虚拟机故障切换到灾备站点。
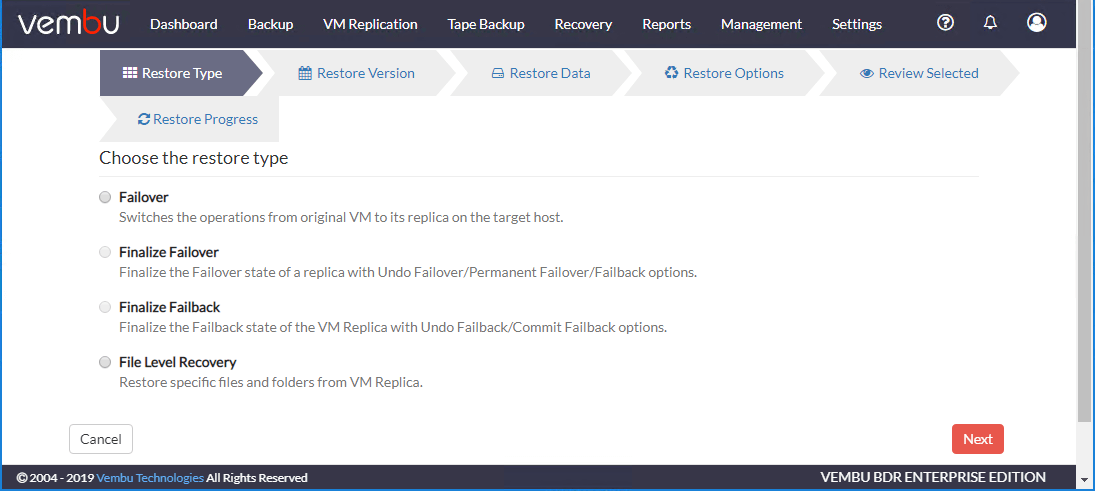
选择恢复的版本用于复制副本VM的故障切换。
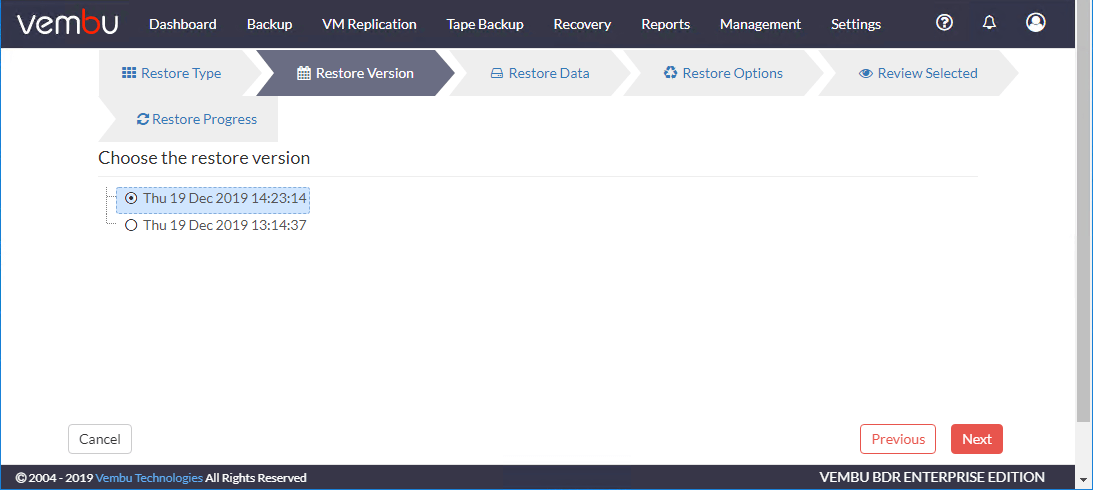
选择恢复数据选项。选择虚拟机您希望进行故障转移。
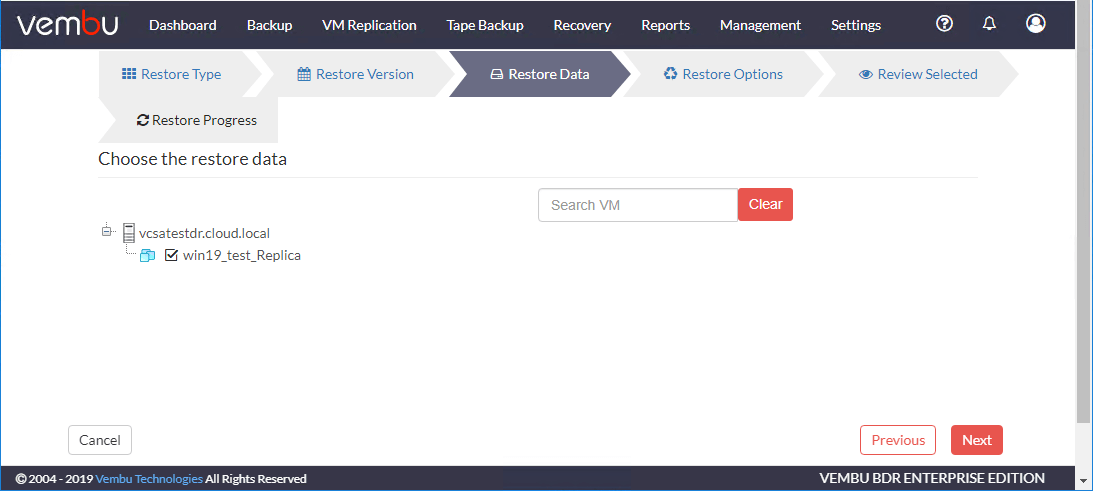
检查您的选择和配置。
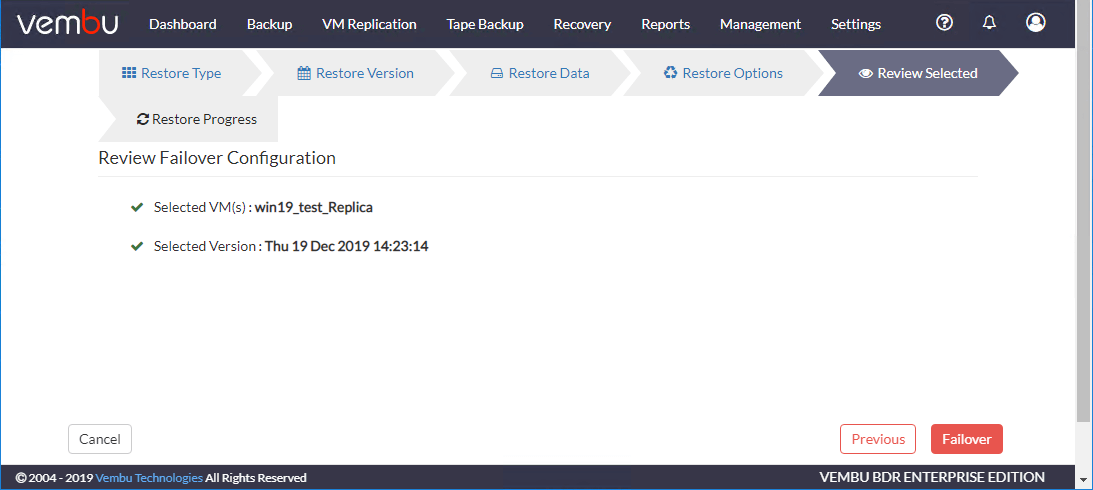
点击好啊继续修复工作。

在监控容灾环境时,会看到灾备站点虚拟机上电,Prod站点虚拟机下电。
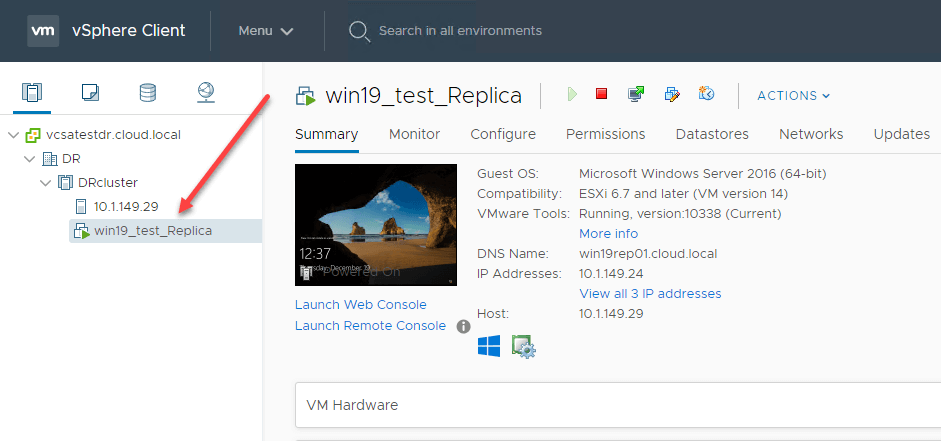
您可以查看复苏的报告用于故障转移操作。
此外,复制向导中包含的网络映射自动化允许配置网络更改,包括虚拟机连接的端口组以及为复制的虚拟机分配的IP地址。
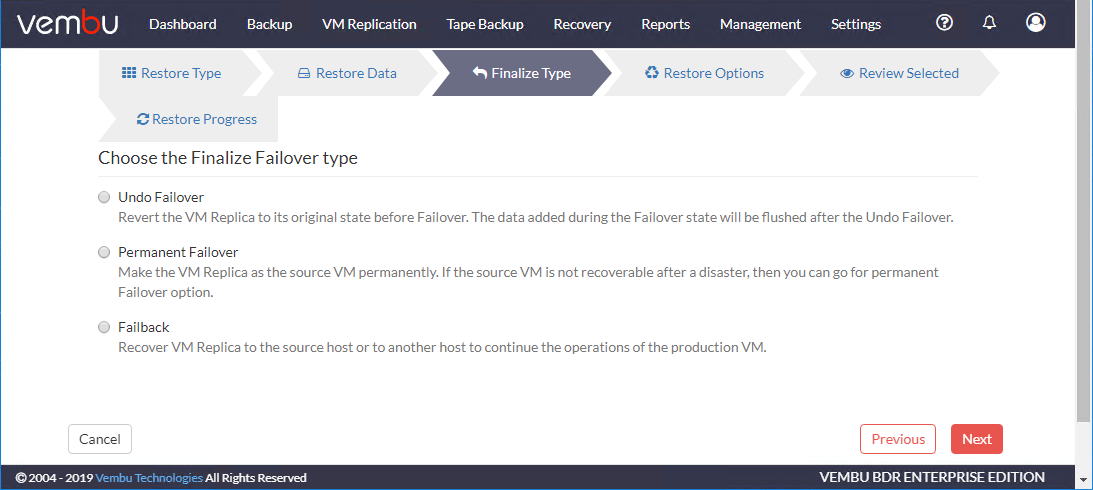
在执行故障转移之后,Vembu允许您执行以下操作完成故障转移.
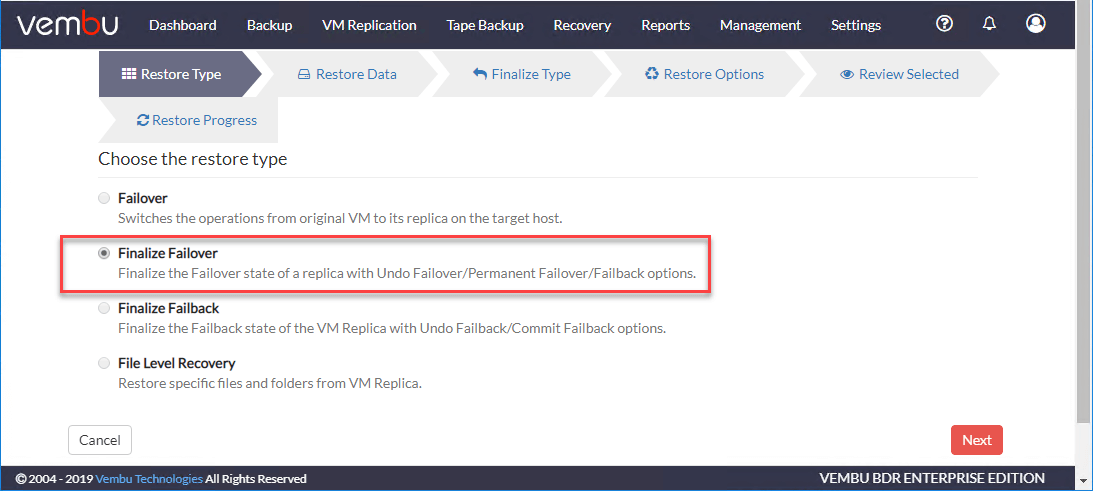
当你选择完成故障转移,你可以看到你的选项如下:
- 消除故障转移—在“故障切换”前将虚拟机副本恢复到原来的状态。在故障转移状态期间添加的数据将在撤销故障转移之后刷新。
- 永久故障转移—将该虚拟机Replica永久作为源虚拟机。如果源VM在灾难发生后不可恢复,那么可以使用永久故障转移选项。
- 退回–将虚拟机复制副本恢复到源主机或其他主机,以继续生产虚拟机的操作
有了这些选项,您可以根据灾难场景决定故障切换操作的持久性和运行生产工作负载的复制VM。
通过Vembu BDR Suite中的复制和故障转移/故障恢复自动化,您可以拥有所需的工具来启用业务连续性,即使您的生产位置已经关闭。网络自动化有助于确保重新配置网络设置的繁琐任务自动完成。
收尾
业务连续性计划是处理灾难场景的整个过程中极其重要的一部分。BCP考虑了“一切”,而不仅仅是环境的技术方面。这包括人力资源、资产、地点和其他在业务运营中需要考虑的因素。
使用VM复制支持业务连续性计划,因为它允许您重新定位生产工作负载运行的位置,从而保持业务运行。即使在站点级完全失败的情况下,VM复制也允许备用站点准备好承担生产流量。
Vembu BDR Suite提供了在辅助位置轻松创建副本虚拟机的能力,它还提供了自动化所需的网络更改以及故障转移/故障恢复操作的能力。有了这些可用的自动化功能,它有助于在发生灾难时简化具有挑战性的技术细节。
